STTS
Scaling Compute-Optimal Text-to-Speech Models
Anonymous Authors
Abstract. We introduce STTS, a text-to-speech (TTS) framework that unifies high-fidelity neural audio compression with in-context language modeling at 44.1 kHz. Building on a single-codebook BigCodec modified with Finite Scalar Quantization (FSQ) and multi-scale adversarial losses, our system compresses speech to 0.8--1.2 kbps while preserving fine prosody and timbre. A decoder-only Transformer then generates codec tokens from text and a short reference utterance, enabling real-time speaker adaptation with no extra fine-tuning. We train models from 40M to 70B parameters on datasets of 1K--100K hours and systematically study how model size, data scale, and bitrate affect intelligibility and speaker similarity. Experiments reveal a 1 kbps “sweet spot” that balances fidelity with manageable sequence lengths and identify predictable scaling laws analogous to text-only LLMs, showing how performance improves under increasing compute. STTS thus provides a compute-optimal strategy for large-scale, high-quality TTS at commercial sampling rates.
Overview
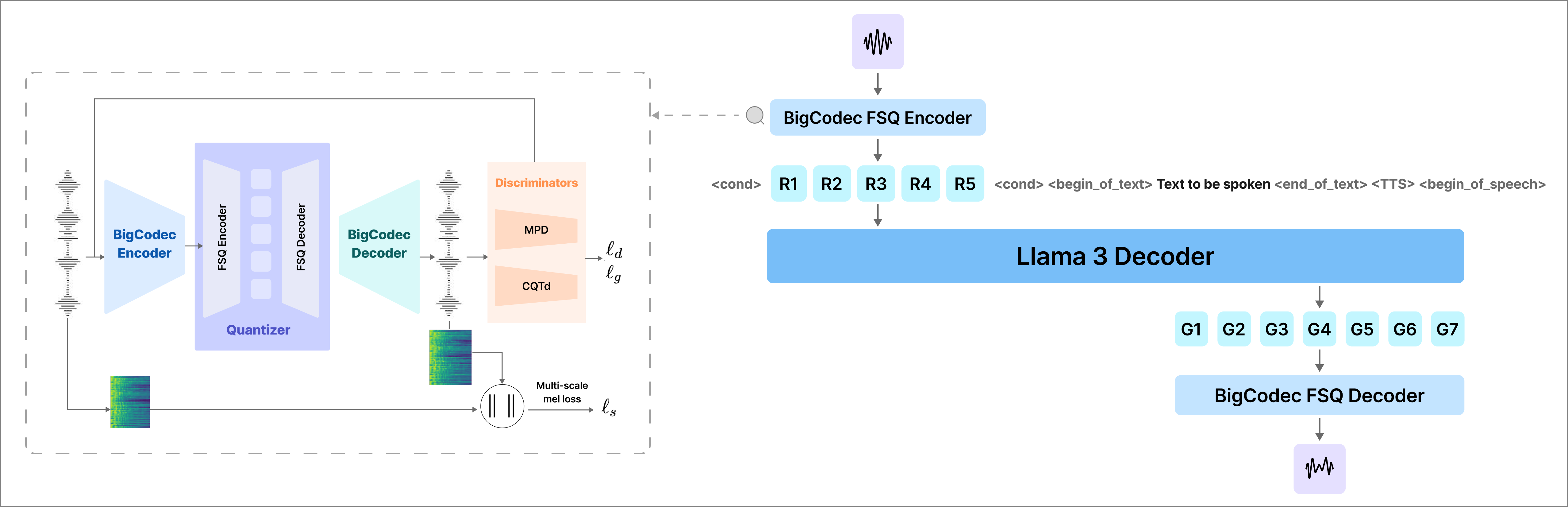
We compress raw 44.1 kHz audio using a single-codebook BigCodec with finite scalar quantization, trained under multi-scale adversarial objectives for low-bit-rate speech reconstruction. The compressed tokens serve as the “audio vocabulary” alongside text tokens for a Llama 3 decoder, which generates output speech tokens autoregressively. This unified model allows in-context speaker adaptation (via reference audio tokens) and text-to-speech generation.
Zero-Shot TTS Samples
| Text | Prompt | STTS |
|---|---|---|
| two thousand two hundred twenty two happily happy two hundred and twenty-two | ||
| As an aficionado of Scandinavian design, Ole Gunnarsson appreciated the principle of "hygge," evident in his Danish home | ||
| Throughout her distinguished diplomatic career spanning five decades and numerous international crises, Ambassador Chen had developed a reputation for finding common ground between opposing factions through careful listening, cultural sensitivity, and an unwavering commitment to humanitarian principle | ||
| As the sun dipped below the horizon, casting a golden glow over the ocean, Emily, who had spent her life dreaming of distant shores, stood on the deck of the ship, feeling a mixture of anticipation and nostalgia as her adventure began. | ||
| With an ample supply of joie de vivre, Mary danced through the streets of Nice, stopping only to enjoy a nice cafe with a warm croissant. | ||
| Can you believe it's been twenty years since we graduated? Sometimes it feels like yesterday we were cramming for finals and planning post-graduation road trips, and other times it seems like several lifetimes ago. I wonder how many of our classmates actually ended up pursuing the careers they thought they would. I certainly never imagined I'd be teaching environmental science in a rural community college, but honestly, I wouldn't change a thing. |
Comparitive Analysis
| - | Speaker Sim↑ | WER↓ |
|---|---|---|
| STTS | 0.408 | 0.055 |
| OpenVoice | 0.259 | 0.003 |
| CosyVoice2 | 0.514 | 0.011 |
| VoiceCraft | 0.451 | 0.012 |
| CosyVoice | 0.464 | 0.011 |
| Text | Prompt | Ground Truth | STTS | OpenVoice | CosyVoice2 |
|---|---|---|---|---|---|
| The difference in the rainbow depends considerably upon the size of the drops, and the width of the colored band increases as the size of the drops increases. | |||||
| Promises were not kept. | |||||
| It is the same in Sweden. | |||||
| When a man looks for something beyond his reach, his friends say he's looking for the pot of gold at the end of the rainbow. | |||||
| If the red of the second bow falls upon the green of the first, the result is to give a bow with an abnormally wide yellow band, since red and green light when mixed form yellow. |